Debugging in Produktion: Chaos Engineering mit eBPF

(Bild: iX)
Observability und Security für zuverlässigen Softwarebetrieb in Produktion: Security-Policies und Datenerfassung verifizieren mit Chaos Engineering und eBPF.
Angesichts der zunehmenden Komplexität moderner Softwareentwicklungs- und Deployment-Infrastrukturen sind Entwicklerinnen und Entwickler auf Methoden und Werkzeuge angewiesen, die eine Automatisierung der Prozesse unterstützen und tiefere Einblicke in die Produktionsumgebung gewähren. Das auf Monitoring, Logging und Tracing aufbauende klassische System-Debugging weicht allmählich dem ganzheitlicheren Ansatz der Observability, die auch in komplexen verteilten Cloud-nativen Umgebungen detailliertere Beobachtungsmöglichkeiten erschließt – um unter anderem den Netzwerkverkehr zwischen Containern in einem Kubernetes-Cluster nachvollziehen zu können.

Dem "Extended Berkley Packet Filter" (eBPF [1]) kommt dabei eine entscheidende und immer wichtiger werdende Rolle zu. Er eröffnet auf Ebene des Linux-Kernels die Möglichkeit, den Netzwerkverkehr und Syscalls zu überwachen. Im Zusammenspiel von eBPF und Observability lassen sich umfassende Informationen aus Metriken, Logs und Traces erschließen, die auch zu mehr Sicherheit beitragen können. Bereits ein Grundverständnis von eBPF und darauf aufbauenden Tools und Frameworks kann helfen, Probleme effizienter zu lösen.
"Extended Berkley Packet Filter [2]" (eBPF) ist eine erweiterte Form des Berkley Packet Filter (BPF), der ursprünglich als Erweiterung des Linux-Kernel zur Netzwerküberwachung angelegt war. eBPF geht mit zusätzlichen Filteroptionen noch darüber hinaus und eröffnet sowohl Systemadministratoren als auch Entwicklerinnen und Entwicklern weitere Einsatzbereiche wie Sicherheit, Observability und Tracing. Anders als direkt ausführbare Netzwerküberwachungstools wie tcpdump lassen sich eBPF-Programme jedoch nur in einem der Sandbox vergleichbaren Verfahren im privilegierten Umfeld des Kernels ausführen.
Ein Just-in-Time-Compiler (JIT) übersetzt den speziellen Bytecode, und ein Verifier stellt vor dem Ausführen der eBPF-Programme sicher, dass sie keine schädlichen Operationen durchführen. Somit sind nicht nur die Sicherheit und langfristige Stabilität der Kernel-Weiterentwicklung gewährleistet, sondern die eBPF-Anwendungen laufen auch mit einer Geschwindigkeit, die der von nativem Kernel-Code nahekommt.
Über die Netzwerkpaketfilterung hinaus lässt sich eBPF unter anderem auch zur Performanceanalyse, Anwendungs- und Netzwerküberwachung sowie -sicherheit und das Syscall-Monitoring nutzen. Über sogenannte Hook Points lassen sich die eBPF-Programme dazu an den geeigneten Stellen im Kernel "einhängen" – etwa an Netzwerkschnittstellen, Tracepoints oder Systemaufrufen. Um darüber hinaus Daten zwischen Kernel- und Benutzerbereich oder zwischen verschiedenen eBPF-Programmen teilen zu können, stehen die eBPF-Maps zur Verfügung. Diese Datenstrukturen unterstützen verschiedene Datentypen und sind damit ein zentrales Merkmal vieler eBPF-Anwendungen.
Den Umgang mit eBPF und das Entwickeln von eBPF-Programmen erleichtern verschiedene Entwicklertools, Frameworks und Bibliotheken – darunter die BPF Compiler Collection (BCC) und bpftrace.
eBPF revolutioniert die Art und Weise, wie sowohl Entwicklerinnen und Entwickler als auch Systemadministratoren Systeme überwachen, debuggen und sichern. Es bietet hohe Flexibilität, ohne die Stabilität oder Sicherheit des Systems zu gefährden.
Weitergehende Informationen und Anregungen zum Lernen liefert auch das Buch "Learning eBPF" von Liz Rice [3].
Erste Einstiegshürden
Welche Tools verwenden eBPF und welche Programmiersprache ist für eigene eBPF-Programme nötig? Der Linux-Kernel erwartet eBPF-Programme im Bytecode-Format oder in Assembler-Code, der sich in Bytecode kompilieren lässt. Für Entwicklerinnen und Entwickler, die vorwiegend höhere Programmiersprachen verwenden, stellen beide Formate eine hohe Einstiegshürde dar. Der LLVM-Compiler clang bietet als erster die Möglichkeit, C-Programme in Bytecode zu kompilieren, und eröffnet damit einer breiteren Developer-Community die Chance, effiziente eBPF-Programme zu schreiben.
Allerdings ist auch für den C-Code sowie die benötigten Header-Dateien ein grundlegendes Kernel-Verständnis erforderlich. Hilfe bieten an dieser Stelle unter anderem der Blog von Brendan Gregg [4] sowie einschlägige Community-Meetups. Dann gelingt es, sich zunächst auf bestehende Tools zu fokussieren, um zu sehen, was möglich ist, und sich Inspiration für erste eigene Programmierversuche zu holen.
Wer die im Folgenden vorgestellten CLI-Tools schnell testen möchte, kann dazu die Workshop-Übungen in einem vom Autor frei zur Verfügung gestellten Projekt auf GitLab [5] nutzen. Dort findet sich eine Lima/Vagrant-Umgebung sowie ein generisches Ansible-Playbook. Alternativ lässt sich anhand des Playbooks auch eine Linux-VM provisionieren, etwa Ubuntu ab Version 22 in der Cloud.
bcc – die BPF Compiler Collection
Zum Einstieg lassen sich die bcc-Tools (BPF Compiler Collection) dazu verwenden, unterschiedlichste Linux-System-Calls und -Komponenten zu überwachen. Das einfachste Beispiel ist das Überwachen ausgeführter Programme wie eines Ping-Kommandos in einer Endlosschleife. Dazu öffnet man zwei Terminals und startet eine While-Schleife mit Ping- und Sleep-Kommando. Im zweiten Terminal führt man execsnoop-bpfcc mit dem -t-Parameter für Tracing aus:
# sudo apt update && apt -y install make clang linux-headers-`uname -r` bpfcc-tools
# 1. Terminal
$ sudo execsnoop-bpfcc -t
# 2. Terminal
$ while true; do ping -c 1 heise.de; sleep 1; doneAbbildung 1 zeigt die resultierende Ausgabe.
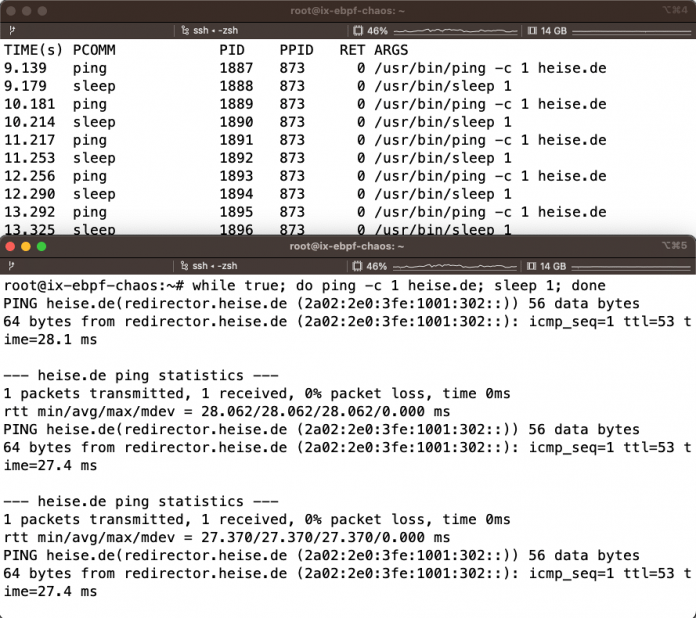
Die bcc-Tools umfassen zwei Komponenten: Im User-Space lassen sich Python-Programme verwenden, die beim Ausführen das Kernel-eBPF-Programm kompilieren und den Bytecode zur Laufzeit in den Kernel laden. Nachteil dabei ist, dass die Buildtools und Kernel-Header auf dem Zielsystem zu installieren sind, was nicht auf allen Produktionssystemen – unter anderem aus Sicherheitsgründen – möglich ist. Darüber hinaus ist das Kompilieren und Laden deutlich langsamer – ein Nachteil, wenn man schnell Probleme debuggen möchte.
Tracing mit bpftrace
Bpftrace, eine Tracing-Hochsprache für BPF, hilft bei der Problemanalyse mit einer Reihe praktischer einzeiliger Kommandofolgen (One-Liner [6]). Sie erleichtert insbesondere Einsteigern das Leben, wenn es darum geht, schnell Systemmetriken und Trace-Endpunkte auszulesen. Darüber hinaus sind Tools wie opensnoop.bt für den Syscall open() verfügbar, die überwachen, ob Prozesse Dateien öffnen (siehe Abbildung 2). Bpftrace benötigt für einzelne Befehle spezielle Debug-Symbole, die sich wie in Listing 1 gezeigt aus dem ddeb.ubuntu.com-Repository [7] installieren lassen.
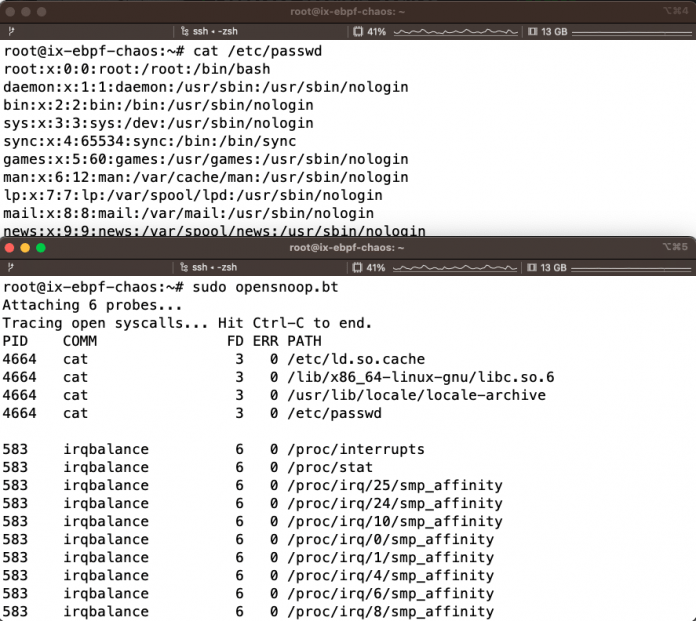
Listing 1: Tracing mit bpftrace
$ echo "deb http://ddebs.ubuntu.com $(lsb_release -cs) main restricted universe multiverse
deb http://ddebs.ubuntu.com $(lsb_release -cs)-updates main restricted universe multiverse
deb http://ddebs.ubuntu.com $(lsb_release -cs)-proposed main restricted universe multiverse" | \
sudo tee -a /etc/apt/sources.list.d/ddebs.list
$ sudo apt install ubuntu-dbgsym-keyring
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F2EDC64DC5AEE1F6B9C621F0C8CAB6595FDFF622
$ sudo apt-get update
$ sudo apt -y install bpftrace bpftrace-dbgsym
$ sudo opensnoop.bt
# 2. Terminal
$ cat /etc/passwdDas erste eBPF-Programm entwickeln
Netzwerkdaten lassen sich am einfachsten analysieren und bieten zudem die Möglichkeit, verschiedene Filter für TCP, UDP, ICMP und andere Protokolle zu testen. Im Folgenden soll daher ein erstes eBPF-Programm mit Fokus auf Netzwerkdaten mit dem eXpress DataPath (XDP-Netzpaketprozessor aus dem IO-Visor-Projekt [8]) erstellt und am Loopback-Interface getestet werden.
Ergänzend zum klassischen C-Code für eBPF-Programme haben sich einige Bibliotheken entwickelt, die es erlauben, abstrahierten Code zu schreiben und sich auf wesentliche Programmabläufe zu fokussieren. Im Go-Umfeld gibt es die beiden populären Bibliotheken cillium/epbf-go [9] und aquasecurity/libbpfgo [10], die in den Open-Source-Projekten Cilium und Tracee zum Einsatz kommen und kontinuierlich weiterentwickelt werden.
Die Rust-Bibliothek aya-rs erlaubt es beispielsweise, die Kernel-eBPF- sowie Userspace-Programme im gleichen Kontext zu schreiben, und sie übernimmt mit Cargo als Build-Umgebung das Kompilieren und Laden der eBPF-Programme (siehe Listing 2). Das erleichtert das Entwickeln ungemein, da der Bytecode automatisch in den Kernel geladen wird. Das aya-rs-Projekt [11] hält zudem hilfreiche Tutorials für die Arbeit mit dem XDP bereit.
Listing 2: Rust-Bibliothek aya-rs
git clone https://github.com/aya-rs/book/
cd book/examples/xdp-hello
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source "$HOME/.cargo/env"
rustup install stable
rustup install nightly
# eBPF-Programm bauen
cargo xtask build-ebpf
# Userspace bauen
cargo build
# 2. Terminal
ping o11y.love
# 1. Terminal: Starten, mit sichtbarem Log-Level
RUST_LOG=info cargo xtask run
[2023-08-04T02:15:28Z INFO xdp_hello] received a packetKlassisches System-Debugging
Die IT-Umgebungen arbeiten immer langsamer, die Festplatten sind voll und vor lauter Containern ist das Problem nicht mehr zu erkennen. Diese Situation dürfte vielen allzu bekannt vorkommen, denn moderne Infrastrukturen für die Softwareentwicklung und deren Deployment sind hochgradig komplex.
Die Online-Konferenz Mastering Observability [12] am 11. Juni 2024 zeigt, wie ein ganzheitlicher Observability-Ansatz dabei hilft, Softwaresysteme zu verstehen, zu steuern und zu verbessern. Die von iX und dpunkt.verlag organisierte Online-Konferenz richtet sich an Entwicklerinnen, Entwickler, Ops-Fachleute und DevOps-Teams, die Probleme in CI/CD, Deployment und Operations schneller aufspüren wollen und den Ursachen auf den Grund gehen möchten – mit dem Ziel, Mängel gezielt zu beheben und in Zukunft möglichst zu vermeiden.
Interessierte können sich jetzt für die Mastering Observability anmelden [13] – das Ticket kostet bis 13. Mai 2024 zum Frühbucherpreis 229 Euro, danach dann 279 Euro (alle Preise zzgl. MwSt.). Gruppen ab drei Personen erhalten im Ticketshop darüber hinaus automatisch mindestens 10 Prozent Rabatt.
Wer über den Fortgang der Konferenz Mastering Observability auf dem Laufenden bleiben möchte, kann sich auf der Website für den Newsletter registrieren [14] oder den Veranstaltern auf LinkedIn [15] folgen – der aktuelle Hashtag lautet #masteringobs [16].
Entwicklerinnen und Entwickler sind zunehmend auf Werkzeuge angewiesen, die detailliertere Einblicke liefern und zur Automatisierung der Arbeit beitragen. Dazu muss nicht jeder eBPF vollständig verstehen oder programmieren können. Wenn allerdings Tools, die eBPF verwenden, nicht korrekt funktionieren, kann dieses Wissen dazu dienen, ihnen wieder auf die Sprünge zu helfen oder bei der Fehlersuche Zeit zu sparen. Manchmal fehlt es lediglich an den Berechtigungen, ein eBPF-Programm in den Kernel zu laden, ein andermal tritt ein Bug nur mit bestimmten Kernel-Versionen auf. Neben den bereits vorgestellten CLI-Tools haben sich in den vergangenen Jahren verschiedene Use-Cases für eBPF entwickelt.
Observability mit eBPF
Über die gängigen Observability-Datentypen mit Metriken, Logs und Traces hinaus gestalten sich die Anforderungen in verteilten Cloud-nativen Umgebungen noch deutlich komplexer. Um etwa den Netzwerkverkehr zwischen Containern in einem Kubernetes-Cluster zu messen, muss man schon etwas tiefer in die Trickkiste – und zu eBPF – greifen. Inspektor Gadget ist beispielsweise eine Tool-Sammlung zum Debuggen verschiedener Kubernetes-Probleme. Das reicht von System-Event-Tracing über Resource-Top-Monitoring bis hin zu Profiling und Auditing.
Einen Anwendungsfall für eBPF hat Cloudflare im Jahr 2019 gestartet: ein Prometheus-Exporter (ebpf_exporter), der mittels eBPF Low-Level-Kernel-Metriken sammeln und exportieren kann (siehe Listing 3 und Abbildung 3). Dadurch eröffnen sich tiefere Einblicke in die System-Performance, um beispielsweise Disk-IO oder TCP-Antwortzeiten in großen verteilten Umgebungen besser analysieren und optimieren zu können. Um Abhängigkeitsproblemen mit den Bibliotheken libbpf und libpbfgo auf dem Host aus dem Weg zu gehen (der ebpf_exporter greift auf libbpf zurück), sollten Entwicklerinnen und Entwickler ein Docker-Image erstellen, um die Binaries zu bauen und dann den Container starten. Dabei empfiehlt es sich, mindestens Kernel 6.1 zu verwenden und aus den Sources zu kompilieren.
Listing 3: Cloudflare Prometheus-Exporter
# Ubuntu 23 VM
git clone https://github.com/cloudflare/ebpf_exporter
cd ebpf_exporter
make build
cd examples && make build && cd ..
sudo ./ebpf_exporter --config.dir examples --config.names accept-latency,bpf-jit,cachestat,cgroup,llcstat,oomkill,raw-tracepoints,shrinklat,tcp-syn-backlog,tcp-window-clamps,timers,uprobe,usdt
# Open localhost:9543 in your browser
http://localhost:9435/metrics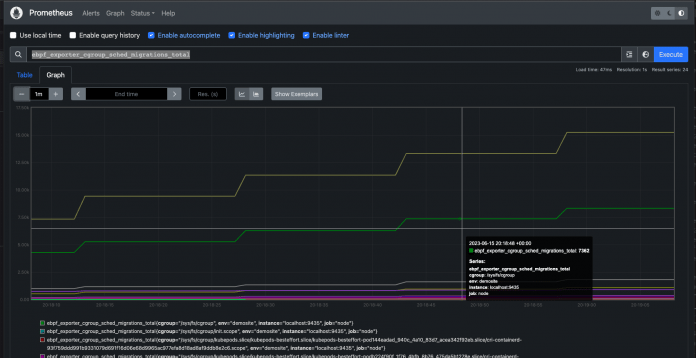
Das CNCF-Projekt (Cloud Native Computing Foundation) OpenTelemetry investiert ebenfalls in eBPF [17]: Der noch recht neue eBPF-Collector für Linux-Host-Systeme, Cloud und Kubernetes verspricht verschiedene Vorteile gegenüber einem Prometheus Exporter [18]. Im sogenannten Reducer-Prozess lassen sich die Metriken mit Metadaten anreichern und direkt an den OpenTelemetry Collector schicken.
Ein weiterer Anwendungsfall für eBPF zielt auf die Effizienz von Entwicklerinnen und Entwicklern ab: Um Traces aus eigenen Applikationen an OpenTelemetry zu schicken, müssen sie den Code instrumentieren, Anpassungen vornehmen, das Software Development Kit (SDK) verstehen und unter Umständen komplexe Probleme der eigenen Architektur lösen. Das limitiert den Einsatz von OpenTelemetry, da viele Entwicklungsteams nicht das notwendige Wissen und die Ressourcen für Observability haben. Einige experimentierfreudige eBPF-Experten haben inzwischen einen Weg gefunden, um Kernel-Events und Funktionsaufrufe mit Debug-Symbolen zu korrelieren und Auto-Instrumentation mit eBPF anzubieten. Die Vorgehensweise ist dabei für jede Programmiersprache unterschiedlich, aber es haben sich bereits eine Reihe von Projekten und Anbietern gefunden, die Innovation in diesem Sektor vorantreiben – im Speziellen für Continuous Profiling.
Parca beispielsweise sammelt mit einem Agenten Performance-Profile von laufenden Applikationen, die sich anschließend für Debugging und Performance-Analyse verwenden lassen (siehe Abbildung 4). Parca [19] steht als Open Source unter Apache-2.0-Lizenz auf GitHub frei zur Verfügung. Es stellt eine Server- und eine Agent-Komponente bereit, die sich als Binary, Docker-Container oder Kubernetes-Deployment starten lassen. Der Agent verwendet eBPF, um Performance-Profile zu sammeln. Die Firma Polar Signals, die Parca ursprünglich entwickelt hat, bietet eine Columnar-Datenbank namens FrostDB [20], mit der sich die Profile performant speichern lassen.
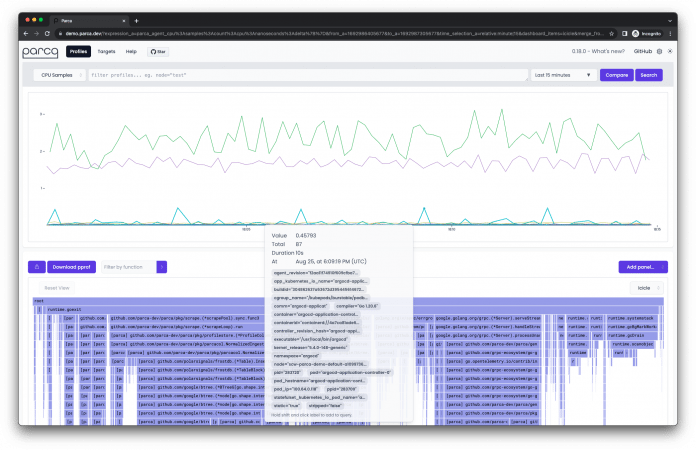
Continuous Profiling gilt als der neue Weg, automatische Performance-Profile zu sammeln. Viele Anbieter folgen diesem Ansatz, wie unter anderen Grafana Pyroscope, Datadog Profiler und Elastic Profiling zeigen. Beim Continuous Profiling dienen Flamegraphs dazu, Callstacks zu visualisieren – den bisher notwendigen Umweg über perf oder vergleichbare Leistungsanalyse-Tools können sich Developer sparen.
Kubernetes Observability mit auto-discovery
Die Anbieter von Observability-Plattformen setzen zunehmend auf eBPF. Datadog hat unter anderem einen Agenten mit eBPF ausgestattet, um per Auto-Discovery mehr Einblicke sammeln zu können. Das neue Open-Source-Projekt Coroot hat sich Kubernetes-Observability auf die Fahnen geschrieben. Ein innovatives Feature sind die Service Maps, die Coroot anhand der Container-Kommunikation mit TCP-Paketen sowie den Kubernetes-API-Metriken dynamisch erstellt und visualisiert. Nutzerinnen und Nutzer erhalten somit auch ohne Konfigurationsaufwand direkt einen Überblick über Services und Deployments und können unmittelbar mit der Analyse und Fehlersuche beginnen.
Die Installation von Coroot [21] gestaltet sich einfach: In der Dokumentation lassen sich die entsprechenden Features aus- oder abwählen. Anschließend steht wie in Listing 4 gezeigt ein Kommando zum Installieren des Helm-Charts parat. Nach erfolgreicher Installation präsentiert die Coroot-Oberfläche die Service Map mit der Möglichkeit, in die einzelnen Services und Nodes hineinzoomen zu können (siehe Abbildung 5). Über die klassischen Observability-Praktiken hinaus eröffnet Coroot auch die Option, Out-of-Memory-Probleme frühzeitig zu erkennen.
Listing 4: Coroot-Installation
# Helm, kubectl, Minikube muss installiert sein, damit Coroot in einem neuen Kubernetes Cluster installiert werden kann. Alternativ kann man auch bei einem Cloud-Anbieter einen Kubernetes-Cluster starten, beispielsweise Civo Cloud.
civo kubernetes create ix-ebpf-chaos
civo kubernetes config ix-ebpf-chaos -s
kubectl config use-context ix-ebpf-chaos
# Podtato-head demo https://github.com/podtato-head/podtato-head
git clone https://github.com/podtato-head/podtato-head.git && cd podtato-head
helm install podtato-head ./delivery/chart
# Coroot
helm repo add coroot https://coroot.github.io/helm-charts
helm repo update
helm install --namespace coroot --create-namespace --set pyroscope.enabled=false --set pyroscope-ebpf.enabled=false --set clickhouse.enabled=false --set opentelemetry-collector.enabled=false --set node-agent.otel.tracesEndpoint="" coroot coroot/coroot
kubectl --namespace coroot port-forward service/coroot 8080:8080
# http://localhost:8080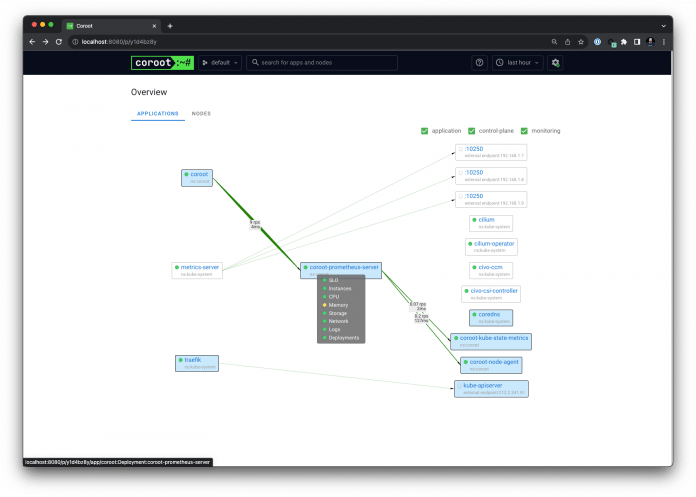
Neben Coroot beherrscht auch Caretta von Groundcover [22] das Erstellen dynamischer Service Maps. Caretta sammelt die Metriken und visualisiert sie in Grafana-Dashboards. Pixie [23] bietet auf Entwicklerinnen und Entwickler zugeschnittene Kubernetes-Observability, inklusive einer High-Level-Abfragesprache, Weathermaps und detaillierteren Einblicken in Applikations-Deployments, ohne dass Code-Änderungen notwendig sind.
Bessere Security durch Observability
Der Anspruch, nicht nur System-Performance-Daten zu verarbeiten, sondern auch Schwachstellen und potenziell bösartige Events zu überwachen, ist nicht grundsätzlich neu. Doch die Kombination von Security-Überwachung mit Observability-Praktiken eröffnet dabei neue, innovative Wege. Der Begriff Observability meint zunächst das Sammeln von Daten und Events, anhand derer sich jederzeit Fragen zum Zustand der Systeme (Health) stellen lassen. Durch Korrelieren der gesammelten Daten eröffnen sich zudem Einblicke in sogenannte Unknown Unknowns (Dinge, von denen man nicht weiß, dass man sie nicht kennt), die insbesondere auch im Hinblick auf sicherheitsrelevante Vorkommnisse und Abhängigkeiten wertvolle Informationen liefern können.
Sicherheit in Kubernetes-Clustern [24] zu gewährleisten ist ein langwieriges Unterfangen, eine vom Start weg 100-prozentig sichere Konfiguration kaum möglich. Unterstützung erhalten Entwicklerinnen und Entwickler dabei durch einige Open-Source-Projekte, die geeignete Werkzeuge an die Hand geben, um direkte Einblicke in Cloud-native Dienste und die Kommunikation im Cluster zu erhalten.
Das auf die Firma Isovalent zurückgehende OSS-Projekt Cilium zählt hier zu den Vorreitern, die auch den Weg für eBPF geebnet haben. Damit lassen sich viele Anwendungsfälle abbilden, von Visibility über Security bis zur Kontrolle von Netzwerken. Cilium lässt sich unter anderem als Load-Balancer im High-Performance Computing einsetzen, bietet transparente Verschlüsselung, Routing und nicht zuletzt auch Observability (mit dem Hubble-Interface). Letzteres eignet sich für den Einstieg in die Arbeit mit Cilium, bevor es an fortgeschrittenere Themen wie Traffic-Routing und Load-Balancing oder gar Service-Meshes in Kubernetes-Clustern geht.
Mithilfe der Dokumentation lässt sich Cilium einfach in Kubernetes-Clustern installieren [25], zur Validierung ist lediglich das Cilium CLI (Command Line Interface) nötig. Anstelle des CNI (Container Network Interface) Flannel lässt sich im speziellen Fall eines Civo-Kubernetes-Clusters Cilium auch direkt mit dem Kommando civo kubernetes create ix-ebpf-chaos --cni-plugin cilium als CNI-Plug-in installieren [26].
Im Rahmen des Cilium-Projekts steht seit Sommer 2022 mit Tetragon [27] ein Werkzeug zur Verfügung, das auf Basis von eBPF bestimmte Syscalls überwachen und bösartige Kommandos unterbinden kann. Mittlerweile hat das Cilium-Team sehr viele Beispielkonfigurationen für Tracing-Policies [28] gesammelt, die sich am Kubernetes-Konfigurationsformat orientieren, wie Listing 5 zeigt. Sie ermöglichen es, bestimmte Typen – etwa den Syscall openat() für Dateizugriffe – oder auch bestimmte Befehle wie cat hinzuzufügen (siehe Listing 6 und Abbildung 6). Mit diesem Wissen lassen sich weitere Policies definieren. Darüber hinaus erlaubt es Tetragon beispielsweise, mit SIGKILL auf Kernel-Ebene entsprechende Operationen direkt zu verhindern. Weitergehende Informationen zu Tetragon stehen in der Dokumentation für Linux und Kubernetes-Cluster bereit.
Listing 5: Tracing-Policy-Konfiguration
$ vim tracing_policy.yaml
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "cat-open"
spec:
kprobes:
- call: "sys_openat"
syscall: true
args:
- index: 0
type: "int"
- index: 1
type: "string"
- index: 2
type: "int"
selectors:
- matchBinaries:
- operator: In
values:
- "/usr/bin/cat"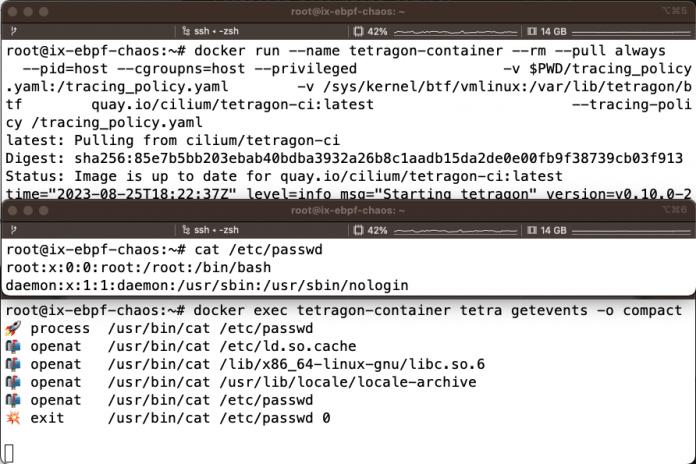
Listing 6: Tetragon Collector
# Ubuntu 23 VM, mit Docker: https://docs.docker.com/engine/install/ubuntu/
# 1. Terminal: Tetragon Collector
docker run --name tetragon-container --rm --pull always \
--pid=host --cgroupns=host --privileged \
-v $PWD/tracing_policy.yaml:/tracing_policy.yaml \
-v /sys/kernel/btf/vmlinux:/var/lib/tetragon/btf \
quay.io/cilium/tetragon-ci:latest \
--tracing-policy /tracing_policy.yaml
# 2. Terminal: Tetragon CLI
docker exec tetragon-container tetra getevents -o compact
# 3. Terminal: cat-Befehl
cat /etc/passwdTracee von Aqua Security [29] verfolgt einen ähnlichen Ansatz. Das CLI-Werkzeug bietet verschiedene Erkennungsmöglichkeiten in den Bereichen Runtime Security und Forensik. Die Dokumentation zu dem OSS-Tool hält neben Paketen für unterschiedliche Plattformen auch Docker-Container und Kubernetes-Deployments parat.
Falco [30] eröffnet die Möglichkeit, Security-Threats in Echtzeit zu erkennen. Das OSS-Framework lässt sich auch zur Überwachung von Containern einrichten, um etwa darin installierte Paket-Abhängigkeiten zu überwachen. Attacken, die in der Praxis häufig zu finden sind, erfolgen beispielsweise über Manipulationen in der package.json-Konfigurationsdatei für Node.js. Dabei überschreiben Angreifer die script-Sektion mit einem harmlos wirkenden curl-Befehl, der ein Script aus dem Internet herunterlädt, das nach dem curl-pipe-bash-Muster ausgeführt wird. Dadurch öffnet der Befehl npm install ein Einfallstor für Angreifer. Je nach Art der Attacke werden bösartige Reverse-Shells, Rootkits oder auch Bitcoin-Miner im System – und unter Umständen auch der CI/CD-Infrastruktur – installiert. Diese Methode fällt in den Bereich der Software-Supply-Chain-Attacken. Um solchen Angriffen auf die Spur zu kommen, ist unter anderem der GitLab Package Hunter für Falco [31] entstanden.
Alles im Griff? – Nicht ohne Validierung!
Die IT-Umgebung läuft, Observability-Tools sind installiert – damit sollte die Arbeit abgeschlossen sein. Nicht ganz, denn um sicherzugehen, dass im Fehlerfall auch tatsächlich alle Metriken gesammelt oder bösartige Dienste sofort erkannt werden, fehlt noch eine Validierung der Konfiguration.
Im Umfeld von Observability und Service Level Objectives (SLOs) [32] lassen sich etwaige Produktionsausfälle mit den Praktiken des Chaos Engineering [33] simulieren. Das funktioniert auch mit einigen der vorgestellten Tools. Eine Validierung von Coroot etwa ermöglichen CPU-Stresstests und Chaos-Experimente mit dem Netzwerkverkehr, um erhöhte Werte im GUI zu prüfen, wenn der CPU-Verbrauch auf den Nodes steigt oder Container untereinander mehr Traffic generieren. Der eBPF-Exporter für Prometheus lässt mit den gleichen Experimenten testen. Ergänzend empfehlen sich hier noch Experimente mit verlangsamender Disk-IO.
Sicherheitsvorfälle hingegen sind schwieriger zu simulieren. Hierzu bietet sich an, bestimmte Tracing-Policies und Events zu triggern, die dann in Cilium Tetragon oder Tracee auftauchen sollten. Beispiele sind etwa der Versuch von Privilege Escalations oder verdächtige Zugriffe auf Dateien (/etc/password zum Beispiel).
Aktive Malware wie Bitcoin-Miner in Kubernetes-Clustern oder CI/CD-Pipelines sind deutlich schwieriger zu erkennen. Dazu bedarf es zusätzlicher Muster-Heuristiken, die sich mithilfe von trainierten Machine-Learning-Modellen besser erkennen lassen. Wie sind beispielsweise Rootkits im System zu entdecken? Um Cilium Tetragon und Tracee zu testen, kann man beispielsweise ein Rootkit installieren und beobachten, was passiert. Solche Experimente sollten jedoch nicht in Produktionsumgebungen erfolgen. Stattdessen empfiehlt sich eine vom Netzwerk abgeschottete virtuelle Maschine (VM) mit einem möglichst aktuellen Linux wie Ubuntu 23. Diese VM reicht für erste Tests und sollte anschließend auch wieder vollständig gelöscht werden. Das Diamorphine Rootkit lässt sich wie in Listing 7 zu sehen als Kernel-Modul laden. Es versteckt sich selbst und überschreibt bestimmte Syscalls, um Dateien zu verstecken und um Root-Rechte zu erlangen. Es ist daher nicht zu erkennen, dass ein Rootkit im Hintergrund läuft (siehe Abbildung 7).
Listing 7: Diamorphine Rootkit
# Docker https://docs.docker.com/engine/install/ubuntu/
# Kernel header, build tools
apt -y install linux-headers-`uname -r` make clang gcc
# Diamorphine Rootkit laden
git clone https://github.com/m0nad/Diamorphine
cd Diamorphine
make
insmod diamorphine.ko
lsmod | grep dia
# Tracee erkennt überschriebene Syscalls, die auf ein Rootkit hindeuten
docker run \
--name tracee --rm -it \
--pid=host --cgroupns=host --privileged \
-v /etc/os-release:/etc/os-release-host:ro \
-v /sys/kernel/security:/sys/kernel/security:ro \
-v /boot/config-`uname -r`:/boot/config-`uname -r`:ro \
-e LIBBPFGO_OSRELEASE_FILE=/etc/os-release-host \
-e TRACEE_EBPF_ONLY=1 \
aquasec/tracee:0.17.0 \
--events hooked_syscalls
# Rootkit entladen https://github.com/m0nad/Diamorphine#uninstall
# Übung: Wenn das Rootkit wieder sichtbar ist, Tracee noch einmal laufen lassen und die Ergebnisse vergleichen.
kill -63 0
rmmod diamorphine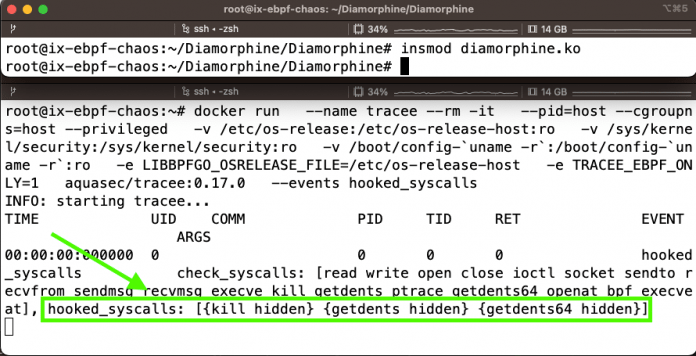
Chaos Engineering mit Hilfe von eBPF
Chaos-Experimente hängen stark vom Anwendungsfall ab. Im Wesentlichen geht es darum, etwas professionell kaputt zu machen und zu beobachten, wie sich Systeme und Anwendungen im Fehlerfall verhalten. Zum Erstellen der Experimente haben sich verschiedene Tools und Frameworks für Chaos Engineering entwickelt, die sich mittels Weboberfläche und CLI bedienen lassen. Ebenso sollen Experimente unter Umständen in zeitlichen Abständen wiederholt werden, um bestimmte Fehlerszenarien zu simulieren. Dazu kommen Schedules zum Einsatz.
Neben Chaos Monkey von Netflix [34] haben sich in der Cloud-Native-Community die Open-Source-Projekte Litmus [35] und Chaos Mesh [36] etabliert. Beide Tools kommen mit einer Vielzahl an Chaos-Experimenten, um unter anderem die CPU zu stressen, Disk-IO zu simulieren, TCP-/HTTP-Antworten zu stören oder DNS-Antworten mit falschen Antworten auszustatten. Das DNS-Chaos-Experiment in Chaos Mesh verwendet beispielsweise CoreDNS in Kubernetes, um überschriebene DNS-Records zurückzuliefern.
Ein weiterer, bei Entwicklern beliebter Vertreter im Bereich Chaos Engineering ist das Chaos Toolkit [37], das sich durch ein leichtgewichtiges CLI in Python und seine Extensions auszeichnet. Chaos Toolkit lässt sich beispielsweise als Proxy in CI/CD-Pipelines einbetten, um zu testen, wie Programme auf unerwartete HTTP-Requests und -Antworten reagieren. Memory-Leaks lassen sich so unter Umständen direkt finden.
Was wäre, wenn sich auf Kernelebene ein eBPF-Programm laden ließe, das mittels Maps vom Kernel ausgehend mit dem User-Space kommuniziert? So ließen sich DNS- oder HTTP-Chaos-Experimente überall betreiben, sowohl in Kubernetes als auch in Linux-VMs. Mit dem Projekt XPress DNS [38] existiert dazu bereits ein Proof-of-Concept, der sich in Richtung der Upstream-Projekte Chaos Mesh oder Chaos Toolkit weiterentwickeln ließe. Eine andere Idee ist, ein Rootkit zu simulieren, das Syscalls überschreibt, und dann kontinuierlich die eigene Umgebung zu testen, ob Alarme getriggert werden. Hierfür ließe sich etwa das Diamorphine-Rootkit anpassen, sodass es lediglich noch Syscalls überschreibt und kontinuierlich "nach Hause telefonieren" möchte, aber keine weiteren bösartigen Aktionen ausführt.
DevSecOps mit eBPF
Wer eigene eBPF-Programme entwickelt, sollte diese auch mit CI/CD-Pipelines testen. Dies gestaltet sich in der Regel schwierig, da die Programme als Root in einen laufenden Kernel geladen und wieder entladen werden wollen. Zum Entwickeln empfehlen sich Bibliotheken (Go, Rust, C++), die eine geeignete Build-Umgebung mitbringen, die sich in CI/CD integrieren lässt. Der einfachste Weg ist es, eine Linux-VM mit Kernel-Headern, Compilern und weiteren Build-Tools zu provisionieren, inklusive eines selbstgehosteten CI/CD-Runners, der sicherstellt, dass die Jobs isoliert mit Root-Rechten laufen können und sich Kernel-Lade- und Entladetests durchführen lassen. Ein Beispiel für die Provisionierung mit Ansible findet sich im eBPF-Workshop des Autors [39].
Der eBPF Verifier, der die eBPF-Programme in den Kernel lädt und dabei auf Sicherheit und Qualität prüft, ist derzeit nur in einem laufenden Kernel verfügbar. Es gibt aber Bestrebungen, eine Stand-alone-Variante zu entwickeln, die Continuous Integration erleichtern könnte. Ein Beispiel dafür ist das eBPF-Verifier-Harness-Projekt [40] von Trail of Bits. Ebenso sind Unit-Tests, Laufzeit-Tests und Security-Scanning notwendig. Auch in diesen Bereichen ist in der näheren Zukunft mit Verbesserungen zu rechnen.
Ein weiteres Risiko liegt in der Komplexität von eBPF. Beim Einsatz der Tools muss man den Anbietern blind vertrauen, und riskiert gegebenenfalls eine "Operation am offenen Herzen" – mit Root-Rechten. Darüber hinaus benötigt die eigene IT-Umgebung ein Review erlaubter Operationen, um beispielsweise zu definieren, welche Personengruppen eBPF-Programme laden, privilegierte Container starten oder andere sicherheitsrelevante Aktionen durchführen dürfen. Beim Monitoring geladener eBPF-Programme stellt sich zudem die klassische Frage: "Wer überwacht die Wächter?" – und welches Programm macht was? Denn ein Packet-Loss beispielsweise könnte auf ein geladenes Programm im XDP-Scope zurückgehen, das Pakete verwirft – etwa ein Überbleibsel eines SRE-Produktionstests. Den Überblick über geladene eBPF-Programme behält man am einfachsten mit dem Befehl bpftool prog list.
Ausblick
eBPF ist derzeit in aller Munde, und sicherlich zumindest vereinzelt auch schon im produktiven Einsatz. Ein grundlegendes Verständnis all seiner Funktionen und Möglichkeiten erfordert tiefergehendes technisches Know-how. Wer zunächst nur in den eigenen IT-Umgebungen neue Wege für Debugging-Strategien beschreiten möchte, dem bieten die im Artikel vorgestellten Tools und Plattformen eine Gelegenheit, erste Erfahrungen zu sammeln. Die behandelten eBPF-Basics helfen, die wichtigsten Begriffe zuordnen zu können, ohne gleich zum eBPF-Experten zu werden. Entwicklerinnen und Entwickler sollten damit auch in der Lage sein, im Falle eines auftretenden CVE zu entscheiden, ob Maßnahmen für ein Produktionsupgrade eingeleitet werden sollten oder nicht.
Der Ansatz, mit eBPF in Events und Funktionen hineinzuschauen, ist innovativ und verspricht Entwicklungsteams detaillierte Einblicke in ihre Umgebungen. Die für Observability erforderliche Code-Instrumentierung trägt jedoch auch zur steigenden Belastung der Teams bei. Dennoch dürften sich künftig messbare Effizienzvorteile ergeben, denen aber auch Risiken gegenüberstehen. Denn so nützlich eBPF für Observability-Zwecke ist, es lässt sich ebenso gut für Angriffe und das Ausnutzen von Sicherheitslücken verwenden. Das aus der Security bekannte Katz-und-Maus-Spiel dürfte sich daher auch mit eBPF nicht erledigt haben – bewährte DevSecOps-Praktiken bleiben daher ein Muss für Produktionsumgebungen.
(map [41])
URL dieses Artikels:
https://www.heise.de/-9701665
Links in diesem Artikel:
[1] https://ebpf.io/what-is-ebpf/
[2] https://ebpf.io/what-is-ebpf/
[3] https://www.oreilly.com/library/view/learning-ebpf/9781098135119/
[4] https://www.brendangregg.com/blog/2019-01-01/learn-ebpf-tracing.html
[5] https://gitlab.com/gitlab-de/workshops/observability/learning-ebpf-for-better-observability-ix-2023
[6] https://github.com/iovisor/bpftrace#one-liners
[7] https://wiki.ubuntu.com/Debug%20Symbol%20Packages
[8] https://www.iovisor.org/
[9] https://github.com/cilium/ebpf
[10] https://github.com/aquasecurity/libbpfgo
[11] https://aya-rs.dev/book/start/hello-xdp/
[12] https://www.mastering-obs.de/index.php
[13] https://www.mastering-obs.de/tickets.php
[14] https://www.mastering-obs.de/
[15] https://www.linkedin.com/events/7176578490597543936/about/
[16] https://www.linkedin.com/search/results/content/?keywords=%23masteringobs
[17] https://github.com/open-telemetry/opentelemetry-ebpf
[18] https://github.com/cloudflare/ebpf_exporter
[19] https://www.parca.dev/
[20] https://github.com/polarsignals/frostdb
[21] https://coroot.com/docs/coroot-community-edition/getting-started/installation
[22] https://github.com/groundcover-com/caretta
[23] https://px.dev/
[24] https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
[25] https://docs.cilium.io/en/stable/gettingstarted/k8s-install-default/#k8s-install-quick
[26] https://www.civo.com/blog/calico-vs-flannel-vs-cilium
[27] https://tetragon.cilium.io/docs/getting-started/
[28] https://github.com/cilium/tetragon/tree/main/examples/tracingpolicy
[29] https://aquasecurity.github.io/tracee
[30] https://falco.org/
[31] https://falco.org/blog/gitlab-falco-package-hunter/
[32] https://o11y.love/topics/slo/
[33] https://o11y.love/topics/chaos-engineering/
[34] https://netflix.github.io/chaosmonkey/
[35] https://litmuschaos.io/
[36] https://chaos-mesh.org/
[37] https://chaostoolkit.org/
[38] https://github.com/zebaz/xpress-dns
[39] https://gitlab.com/gitlab-de/workshops/observability/learning-ebpf-for-better-observability-ix-2023/-/blob/main/ansible/learn-ebpf-playbook.yml?ref_type=heads
[40] https://blog.trailofbits.com/2023/01/19/ebpf-verifier-harness/
[41] mailto:map@ix.de
Copyright © 2024 Heise Medien